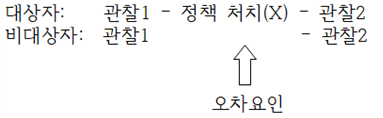
1. 언제 사용하는가?정책이나 제도 개입의 효과를 평가할 때, 단순히 한 집단의 전후 변화만으로는 정책 효과를 입증하기 어렵다. 왜냐하면 시점 간 차이는 정책 외에도 다양한 외생적 요인의 영향을 받을 수 있기 때문이다. 그렇다면 회귀분석으로 통제하면 될까?회귀분석을 이용해서 정책대상자와 비대상자의 모든 차이를 통제할 수 있다면 정책효과를 추정할 수 있다. 하지만 실제로는 다음과 같은 문제가 있다. a. 차이를 유발하는 중요한 속성변수를 연구자가 모를 수 있고 b. 안다고 해도 데이터에 포함되어 있지 않거나 c. 측정 자체가 어려울수도 있다. 이 경우 회귀분석을 통해 원인을 추정하는 방안은 실현하기 어렵다. 그래서 어떻게 할 수 있을까?정책대상자와 유사한 집단을 특정할 수 있다면 정책 개입 전후의 변화를..