1. 언제 사용하는가?
정책이나 제도 개입의 효과를 평가할 때, 단순히 한 집단의 전후 변화만으로는 정책 효과를 입증하기 어렵다. 왜냐하면 시점 간 차이는 정책 외에도 다양한 외생적 요인의 영향을 받을 수 있기 때문이다.

그렇다면 회귀분석으로 통제하면 될까?
회귀분석을 이용해서 정책대상자와 비대상자의 모든 차이를 통제할 수 있다면 정책효과를 추정할 수 있다. 하지만 실제로는 다음과 같은 문제가 있다.
a. 차이를 유발하는 중요한 속성변수를 연구자가 모를 수 있고
b. 안다고 해도 데이터에 포함되어 있지 않거나
c. 측정 자체가 어려울수도 있다.
이 경우 회귀분석을 통해 원인을 추정하는 방안은 실현하기 어렵다.
그래서 어떻게 할 수 있을까?
정책대상자와 유사한 집단을 특정할 수 있다면 정책 개입 전후의 변화를 양 집단에서 비교함으로써 공통된 오차요인들은 제거하고 정책의 순수한 효과만을 추출할 수 있다.
이것이 바로 DID (Difference-in-Differences) 분석의 핵심이다.
완전히 동일한 집단은 아닐지라도 최대한 유사한 집단을 비교함으써 차이의 차이 = 정책효과를 추정할 수 있다.
즉 DID는 통계적 통제가 비현실적이고, 실험도 불가능할 때, 유사한 집단간 전후 변화를 비교함으로써 정책효과를 추출하는 방법이다.
2. DID와 회귀분석의 혼란변수 통제의 차이
DID: “유사한 외부요인의 영향”을 받는 집단 비교
DID(Difference-in-Differences)는 정책 개입의 순수한 효과를 추정하기 위해, 정책의 영향을 받은 처치집단과, 정책은 받지 않았지만 동일한 외부요인(오차요인)의 영향을 받았다고 가정되는 통제집단을 비교하는 방법이다.
즉, DID는 오차요인을 측정하지 않고도 그 영향이 같다고 “가정”되는 집단 간의 전후 차이의 차이를 통해 정책의 효과만을 분리해낸다.
| 시간 1 | 시간2 | |||
| 통제집단 | c1 | → | c2 | 외부요인 |
| 처치집단 | y1 | → | y2 | 외부요인+ 정책효과 |
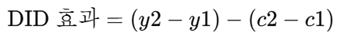
회귀분석: 혼란변수를 직접 측정하고 통계적으로 통제
회귀분석에서의 혼란변수 통제는, 정책효과 외에도 종속변수에 영향을 줄 수 있는 다른 변수들(혼란변수)을 모두 측정해서 회귀모형에 포함시키는 방식이다.
여기서 중요한 것은 연구자가 어떤 변수가 중요한 혼란변수인지 알아야하고, 데이터에 측정되어 있어야 하며, 모형에 올바르게 포함되어 있어야 한다는 점이다.
즉 같은 오차를 받고 있다고 믿을만한 집단을 찾는 것과 오차요인을 모두 알고 모형에 넣는 것의 차이다.
3. 평행 추세 가정
그런데 그런 유사한 집단을 구했다고 해도, 그것이 정말 유사한지 어떻게 확인하나? DID 분석에서 중요한 가정은, 처치집단과 통제집단이 정책 시행 전에는 비슷한 경향으로 변화하고 있었어야 한다는 것이다. 즉, 정책이 없었다면 두 집단의 종속변수는 평행하게 움직였을 것이라는 가정이다. (즉, 평행 추세 가정: parallel trends assumption).
가장 간단한 확인방법은 그림을 보는 것이다. 아래 그림에서 정책시행 이전 시점인 t-2와 t-1에서 두 집단은 의미있는 차이가 없었다. 따라서 처치집단으로 활용가능하다는 것을 보여준다.
육안으로 판단하기 어려울 경우 회귀식을 이용해 검증해 볼 수도 있다. 두 집단의 회귀식이 평행선을 그리는가를 판단하는 것이므로 t-2에서 t-1으로의 변화를 나타내는 변수 (시간)과 두 집단을 나타내는 변수(처치)의 상호작용 항 (시간*처치)
의 계수가 유의미하지 않으면 된다.

4. DID는 어떻게 정책효과를 보여주는가?
일반적인 회귀분석에서는 혼란변수를 통제하기 위해 다양한 오차요인을 모델에 직접 포함시킨다. 하지만 DID(Difference-in-Differences) 모형은 오차요인을 측정하지 않고, 정책 처치 여부(treat)와 처치 시점(post) 두 변수의 상호작용 항(Interaction)을 통해 정책 전후의 두 집단 간 차이를 계산하여 효과를 추정한다.
시점 t1에서 t2의 변화기간 동안 처치집단은 Y2-Y1의 변화가 있었고, 통제집단은 c2-c1의 변화가 있었다. 그런데 정책효과가 없다면 이 두 변화량은 과거에 그랬듯이 비슷할 것이다. 반면에 정책에 효과가 있다면 처치집단의 변화와 통제집단의 변화가 다를 것이라고 보는 것이다. 즉
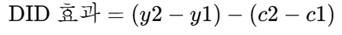
이 된다.
이를 회귀식으로 표현하면 다음과 같다.
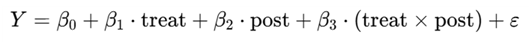
이 식에서 treat는 두 집단 간의 차이다. 이 차이는 동일한 집단이 아니기 때문에 존재하는 차이다. post는 시간의 차이에 따른 변화다. 이것은 두 집단에 공통으로 영향을 준 외부요인들의 영향력이다. 그리고 treat*post가 바로 기간 동안에 차별적으로 나타난 효과 즉 정책처치의 효과를 나타낸다. 따라서 회귀추정결가 b3가 유의미하면 정책효과가 있는 것이고, 그렇지 않으면 정책효과는 없는 것이다.
DID는 결국 일반 선형회귀분석을 실시하되, 혼란변수 대신에 위 식에서 보듯이 시간과 처치여부 그리고 상호작용 항을 사용한 것이다.
주목해야 할 부분은 상호작용 항(treat × post)의 계수와 유의성이다. 이 계수가 통계적으로 유의미하다는 것은, 정책의 효과가 처치집단에서 유의하다는 것을 알해주고, "정책 이후, 처치집단이 통제집단에 비해 얼마나 더 변화했는가?" 를 나타낸다. 즉 정책전후 차이가 집단에 따라 차이가 있는지 (차이의 차이, difference in difference) 그리고 그 차이가 얼마인지를 나타낸다.
상호작용 항이 유의미하면 두 직선은 평행선을 그릴 것이고 유의미하다면 아래와 같이 평행에서 벗어난 형태를 보인다.

6. 두 시점만 있어도 DID 분석이 가능한가?
정책 효과를 추정하는 DID 분석에서 평행 추세 가정을 검토하려면, 정책 시행 이전 시점의 반복 관측 자료가 필요하다. 그러나 현실에서는 이러한 자료가 부족한 경우가 많다. 이처럼 사전 시점이 하나뿐인 경우에는 평행 추세를 실증적으로 확인할 수 없으며, 이로 인해 DID 분석의 결과를 정책 효과로 단정하기 어렵다.
이러한 한계를 보완하기 위해, 집단 간 동질성을 확보하려는 여러 시도가 이루어진다. 예컨대 통제변수를 회귀모형에 포함하거나, 성향 점수 매칭(PSM)을 통해 유사한 비교집단을 구성하는 방법이 대표적이다. 그러나 이러한 방법들이 평행 추세 가정을 충분히 대체할 수 있는지는 여전히 논란의 여지가 있다. 통제변수만으로 집단 간 차이를 충분히 제거하는 것은 예외적인 경우이며, 대부분의 경우 잠재적 이질성이 남아 있을 수 있기 때문이다.
7. 예시: GPT를 이용한 DID 분석
연구문제 예시
청소년 비만 예방 프로그램이 BMI에 미치는 영향을 평가하고자 한다. 2018년 A지역 중학생을 대상으로 비만 예방 교육 프로그램이 시작되었고, B지역은 유사한 사회경제적 특성을 지닌 비교지역으로 지정되어 해당 프로그램이 시행되지 않았다.
데이터 수집 구조
출처: 학교 건강검진 기록, 지역 보건소 협력 조사, 서베이 설문 등
기간: 정책 전후 2년 (2017~2019)
변수: 지역(A/B), 시점(도입 전/후), BMI(연속형), 성별, 연령, 가구소득, 식습관 등 통제변수 포함
분석 기법 선택 이유
단순 회귀로는 전후 차이만 파악 가능하고, 외생변수 영향을 통제하기 어렵다. DID 분석은 지역 간 평행추세 가정을 전제로, 프로그램의 인과적 효과를 추정할 수 있다.
데이터 준비
분석에 사용되는 데이터는 사전에 long-form으로 통합한다. (시점 별로 나뉜 파일은 분석자가 미리 통합하여 GPT에게 제공하는 것이 좋다).
| id | region | year | BMI | sex | age | income |
| 1 | A | 2017 | 23.1 | M | 14 | 3 |
| 2 | B | 2017 | 22.8 | F | 15 | 2 |
| 3 | A | 2018 | 23.0 | M | 15 | 3 |
| 4 | B | 2018 | 22.6 | F | 15 | 2 |
| 5 | A | 2019 | 22.1 | M | 16 | 3 |
GPT 요청:
| 평행추세 검토 평행추세 검토는 별도로 요청해야 한다. 요청하지 않으면 하지 않는다. a. 정책 도입 전 기간인 2017~2018년 A지역과 B지역의 BMI 평균 변화가 유사했는지 그래프로 보여줘. b. 또는 회귀모형에서 time을 더 세분화해서 상호작용 항을 구성해 평행추세 검증을 실시해 줘. 공변량 검토 A지역(treat=1)과 B지역(treat=0) 중학생이 정책 시행 전(2017~2018년)에 성별, 연령, 가족소득, 식습관 변수에서 유사한지 확인해줘. 각 변수별로 평균값이나 분포를 비교하고, t검정 또는 카이제곱검정을 사용해서 두 집단 간 통계적으로 유의한 차이가 있는지도 알려줘. DID요청 아래 변수들을 포함해서 DID 분석을 실행해줘: treat와 post의 상호작용항 포함하고, 통제변수도 추가해줘. - treat: A지역=1, B지역=0 - post: 정책 시행 후(2019년)=1, 이전 연도(2017~2018년)=0 - BMI: 연속형 결과변수 - 성별, 연령, 소득: 통제변수 해석 회귀결과 요약표와 함께 상호작용 항 해석을 포함한 설명도 부탁해. 분석에 사용한 파이선 코드를 전체 출력해 줘. 분석 과정을 재현할 수 있도록 필요한 패키지 import, 데이터 읽기, 회귀실행, 시각화까지 포함해 |
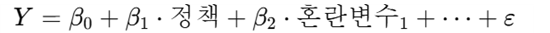
'데이터 분석방법' 카테고리의 다른 글
| PSM과 PSW: 성향점수(Propensity Score)를 이용한 분석 (0) | 2025.04.10 |
|---|---|
| 통계적 통제란 무엇인가? (0) | 2025.03.28 |
| 사회과학에서의 인과적 영향: 매개변수와 조절변수의 역할 (헤이즈 PROCESS Macro 활용) (0) | 2025.03.20 |
| 혼란 변수(Confounding Variables) 통제: 인과관계 분석의 핵심 (0) | 2025.03.14 |
| 두 변수 간 관계분석: 집단 간 차이, 상관도, 동등성 검증 (5) | 2025.03.13 |