챗지피티(ChatGPT)로 로지스틱분석하기 - 말로 하는 데이터 분석
데이터 올리기는 이 블로그의 'GPT로 선형회귀분석 하기' https://skcho.tistory.com/64 을 참조하면 된다. 데이터 올리기와 변수 설명은 생략한다.
1단계: GPT 분석시행
1-1. GTP에게 분석목적과 변수 알려주기
목적
분석목적과 분석방법을 알려주는 것은 gpt 분석에서 가장 중요하다. 그 다음 종속변수를 만드는 방법을 같이 알려주었다.
지시문
| 주관적 건강상태가 신체적 건강상태를 예측해 주는지를 알아보고자 한다. 종속변수는 신체적 건강상태이며, 독립변수는 연령, 주관적 건강상태, 소득, 성별, 교육수준이다. 종속변수인 신체적 건강상태는 heal_prob의 1에서 6까지 변수에서 한 개라도 아프다고 체크한 경우를 1이라고 하고 pheal '신체적 건강상태'로 합시다. |
팁: 변수 구성이 복잡하면 별도로 지시하고 확인하는 것이 필요하다.
지피티 반응
heal_prob1부터 heal_prob6까지 변수 중 하나라도 "1(있음)"으로 체크된 경우pheal = 1,
그 외는 pheal = 0으로 새 변수를 생성했습니다.
pheal변수 분포는 다음과 같습니다:
0 (신체적 건강문제 없음):22,843명
1 (신체적 건강문제 있음):27,352명
1-2. GPT 로지스틱 분석 실시
지시문
| 로지스틱 회귀를 실시하시오. . |
팁: 변수가 여러 개일 경우는 종속변수와 독립변수를 열거해 주는 것이 좋다. 여기서는 분석에 사용될 변수만 남기고 지우라고 했기 때문에 명시하지 않았다.
종속변수:pheal(신체적 건강문제 여부)
독립변수:age, heal_cond2, earning2_r, gender, edu2
모형:로지스틱 회귀 (Logistic Regression)
| 변수 | β | p값 | 해석 방향 |
| (Intercept) | 0.773 | < .001 | 기준 상태의 로그오즈 |
| age | 0.028 | < .001 | 나이 증가 → 건강문제 ↑ |
| heal_cond2 | –0.576 | < .001 | 주관적으로 건강하다 → 건강문제 ↓ |
| earning2_r | 0.0017 | < .001 | 소득 증가 → 건강문제 ↑ (매우 미미함) |
| gender | 0.122 | < .001 | 남성이 건강문제 더 많음 |
| edu2 | –0.311 | < .001 | 고학력일수록 건강문제 |
무엇을 하는가?
사회과학에서는 주로 변수별 영향력이 필요한데, 선형회귀와는 달리 로지스틱에서는 비표준화계수의 오즈비 값으로 변수별 영향력을 본다. 이 오즈비는 exp(b)로 요청한다. 모델 적합도는 Pseudo R square를 구해서 본다.
지시문
| 변수별 영향력과 모델 적합도를 산출해 주시오 |
| 변수 | exp(β) | 영향력 해석 |
| age | 1.028 | 1세 증가 시 건강문제 확률 2.8% 증가 |
| heal_cond2 | 0.562 | 건강하다고 느낄수록 건강문제 확률 43.8% 감소 |
| earning2_r | 1.0017 | 영향 거의 없음 |
| gender | 1.129 | 남성이 여성보다 건강문제 확률 12.9% 높음 |
| edu2 | 0.733 | 고학력자가 건강문제 확률 26.7% 감소 |
모델 적합도
| 지표 | 값 | 해석 요약 |
| Log-Likelihood | –31,257 | 모델의 적합도 |
| Log-Likelihood (Null model) | –34,516 | 독립변수 없이 예측한 적합도 |
| Pseudo R² (McFadden) | 0.094 | 설명력은 중간 수준 |
| AIC | 62,526 | 다른 모델과 비교 가능 |
본 로지스틱 회귀모형은 age, heal_cond2, gender, edu2가 유의미한 예측변수였으며,
특히 주관적 건강상태가 가장 강력한 설명력이 있었다.
모델 적합도는 Pseudo R² = 0.094로 제한적 설명력을 가지지만,
Null 모델 대비 통계적으로 유의미한 향상을 보여주었다.
1-3. GPT 로지스틱의 가정 검토
무엇을 하는가?
모형의 적합도는 어느 정도 있는 것으로 나타났지만, 연령의 효과크기가 상대적으로 낮게 나타나 모형 가정을 검토핼 필요가 있다.
지시문
| 로지스틱 가정을 검토하고자 한다. 다중공선성을 검토하고, Box-Tidwell 검증을 실시하고 해 다오. |
팁:
. 가정을 검토하는 방법이 여러 가지이므로 명시해 주어야 한다.
GPT 반응
다중공선성(VIF) 점검 결과
| 변수 | VIF 값 | 해석 요약 |
| const | 80.92 | 상수항 → 무시 가능 |
| age | 1.55 | 공선성 문제 없음 |
| heal_cond2 | 1.19 | 매우 낮음 |
| earning2_r | 1.02 | 전혀 문제 없음 |
| gender | 1.02 | 문제 없음 |
| edu2 | 1.46 | 낮음 (안정 범위) |
Box-Tidwell 검정 결과 (선형성 가정 점검)
검토한 연속형 변수: age, heal_cond2, earning2_r
각 변수와 그 log값의 상호작용 항(x × log(x))을 포함하여 로지스틱 회귀를 실시한 결과:
| 변수 | P값 | 해석 요약 |
| age_log | 0.139 | ❌ 비유의적 → 선형성 가정 만족 |
| heal_cond2_log | 2.5e-13 | ✅ 유의 → 선형성 가정 위배 가능성 있음 |
| earning2_r_log | 1.8e-04 | ✅ 유의 → 선형성 가정 위배 가능성 있음 |
무엇을 하는가?
가정 검토결과로 볼 때, 주관적 건강상태의 예측력이 연령에 따라 달라지기 때문일 가능성도 있다고 보았다. 비록 연령은 선형성을 유지하고 있지만 다른 변수들이 선형성을 보이지 않았기 때문이다. 이 이 점을 확인할 필요가 있다.
지시문
| 연령과 주관적 건강상태의 상호작용을 확인해 보시오. 상호작용이 유의미한지 그리고 모델 설명령이 증가하는지 보시오. |
팁:
. 가정을 검토하는 방법이 여러 가지이므로 명시해 주어야 한다.
GPT 반응
가정 검토결과로 볼 때, 주관적 건강상태의 예측력이 연령에 따라 달라지기 때문일 가능성도 있다고 보았다. 비록 연령은 선형성을 유지하고 있지만 다른 변수들이 선형성을 보이지 않았기 때문이다. 이 이 점을 확인할 필요가 있다.
✅ 연령 × 주관적 건강상태 상호작용 효과 검토 결과
| 항목 | 결과값 | 해석 요약 |
| Pseudo R² (기본모형) | 0.0944 | 상호작용 전 설명력 |
| Pseudo R² (상호작용 포함모형) | 0.0965 | 설명력 약간 향상 |
| 설명력 증가폭 (ΔR²) | +0.0021 | 매우 작지만 실제 향상 |
| 상호작용 항 유의확률 (p값) | < .0001 | ✅ 매우 유의함 |
무엇을 하는가?
상호작용 계수는 해석이 직관적이지 않다. 집단별로 구분하여 살펴보는 것이 좋다.
지시문
| 연령을 세 집단으로 구분하고 집단별로 로지스틱 분석을 실시해 보시오. 이 때 오즈비를 세 집단별로 나란히 비교하기 좋도록 구성해 주시오. |
팁: 오즈비 비교를 명시하지 않으면 비표준화계수만 보여준다.
집단별 비교하기 편하도록 해야 한 표에 나온다.
연령집단 주관적 건강상태 소득수준 성별 교육수준
---------------------------------------------------------
18–39세 0.6861 1.0003 1.1702 0.7803
40–59세 0.5846 1.0021 1.0412 0.6120
60세 이상 0.4126 1.0018 1.0537 0.6616
주관적 건강상태: 연령이 높을수록 오즈비가 낮아짐 → 건강하다고 느낄수록 실제 건강문제 발생 위험 더 크게 감소
소득수준: 모든 연령대에서 오즈비 거의 1 → 거의 영향 없음
성별: 모든 연령대에서 오즈비 > 1 → 남성이 여성보다 건강문제 확률 약간 높음
교육수준: 중년층(40–59세)에서 가장 강한 보호효과(오즈비 0.61)
1-4. 최종 모형 추정
무엇을 하는가?
유의하지 않은 변수를 제외하고 최종 모형을 추정했다.
논문이나 보고서 제출시에는 유의하지 않은 변수를 제외하고 추정한다.
지시문
| 유의한 것으로 최종모형을 구성해서 통합집단에서의 모델적합도와 오즈비를 변수별로 나타내시오. 연령과 주관적 건강의 상호작용항과 연령이 포함되어야 하고, 주관적 건강, 성별은 제외된다. |
팁:
지피티 반응
모델식: pheal ~ age + heal_cond2 + age × heal_cond2 + gender + edu2
→ 연령, 주관적 건강, 상호작용, 성별, 교육수준 모두 포함
오즈비 (exp(β))
| 변수 | 오즈비 | 해석 요약 |
| Intercept | 0.2337 | 기준군의 오즈 |
| 연령 (age) | 1.0734 | 나이 1세 증가 시 건강문제 확률 7.3% 증가 |
| 주관적 건강상태 (heal_cond2) | 1.0268 | 단독 효과는 미약 (상호작용 중심 해석 필요) |
| 연령×주관적건강 (상호작용) | 0.9883 | 연령 증가 시 주관적 건강 보호 효과 점점 감소 |
| 성별 (gender) | 1.1347 | 남성이 여성보다 건강문제 확률 13.5% 높음 |
| 교육수준 (edu2) | 0.7370 | 고학력자일수록 건강문제 발생 확률 26.3% 감소 |
모델 적합도
| 지표 | 값 | 비교해석 |
| Log-Likelihood | –31,196.45 | 개선됨 |
| Pseudo R² | 0.0962 | 기존 모형보다 ↑ |
| AIC | 62,404.90 | 낮아짐 → 더 좋은 적합도 |
결론 요약
연령, 주관적 건강인식, 성별, 교육수준을 포함한 로지스틱 회귀모형은 건강문제 발생에 유의한 설명력을 보였으며,
특히 연령과 주관적 건강상태의 상호작용 항이 유의하게 나타나,
연령 증가에 따라 “나는 건강하다”는 인식의 보호효과가 점점 감소하는 조절 효과가 존재함을 시사하였다.
모형의 Pseudo R²는 0.0962로, 기본모형 대비 설명력이 향상되었고 AIC 역시 더 낮게 나타나 모형 적합도 역시 개선되었다.
필요하시면 위 결과를 책용 보고서 문단, 표 형태로도 정리해드릴 수 있습니다. 원하시나요?
1_5. 로지스틱의 혼동행렬 및 ROC 플릇
무엇을 하는가?
로지스틱의 예측은 정확도 뿐만 아니라 민감도와 특이도를 같이 보아야 한다.
| 혼동행렬과 AUC를 구하시오. |
본 모형의 정확도는 64.8%, 민감도 68.6%, 특이도 60.3%이며,
AUC는 0.7033으로 양성과 음성을 구분하는 성능이 보통 이상 수준으로 나타났다.
이는 연령과 주관적 건강인식, 그리고 그 상호작용을 고려함으로써
예측력이 향상된 결과로 해석할 수 있다.
1_5. 결과 해석
| APA 스타일에 맞추어 결과를 정리해 주세요. 그리고 분석과정을 포함해서 방법을 기술해 주세요. 회귀계수, 모델적합도, 성능지표를 숫자를 포함해서 보고서 스타일로 자연스럽게 서술하시오. |
📄 방법 (Methods)
분석은 Python 3.9 환경에서 statsmodels, sklearn패키지를 사용하여 수행되었다.
종속변수는 **신체적 건강문제 경험 여부(pheal)**로 이진 로지스틱 회귀모형을 구성하였으며,
주요 독립변수로는 연령(age), 주관적 건강상태(heal_cond2), 성별(gender), **교육수준(edu2)**이 포함되었다.
또한, 연령과 주관적 건강상태 간의 **상호작용 항(age × heal_cond2)**을 추가하여 조절 효과를 검토하였다.
모형의 성능은 로그우도(Log-likelihood), Pseudo R²(McFadden), AIC로 평가하였으며, 예측력 검토를 위해 ROC 곡선과 AUC, 혼동행렬을 산출하였다.
📄 결과 (Results)
🧮 회귀분석 결과
최종모형은 유의한 변수들과 조절효과를 포함하여 다음과 같은 회귀식을 도출하였다
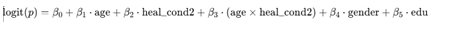
* heal_cond2는 점수가 높을수록 주관적으로 건강하다고 인식하는 방향으로 역코딩되었음.
📊 모델 적합도
Log-Likelihood = –31,196.45
McFadden Pseudo R² = 0.0962
AIC = 62,404.90
→ 모형의 설명력은 제한적이나 기본 모형 대비 향상되었으며, 적합도 또한 개선되었다.
📈 예측 성능지표
정확도 (Accuracy):64.83%
민감도 (Sensitivity):68.57%
특이도 (Specificity):60.34%
AUC (Area Under Curve):0.7033
→ AUC가 0.70 이상으로 나타나, 본 모형이 건강문제 유무를 양성과 음성을 의미있게 구분할 수 있는 성능을 가진 것으로 평가된다.
📄 해석 및 논의
연령은 건강문제 발생에 대해 일관되게 유의미한 예측력을 보였으며,
특히 주관적 건강상태와의 상호작용 항이 유의하게 나타나
연령이 높을수록 "나는 건강하다"는 인식의 보호효과가 점차 줄어드는 조절효과가 관찰되었다.
성별은 남성이 건강문제 경험 확률이 높았고, 교육수준은 고학력일수록 유의하게 낮았다.
소득수준은 초기 모형에서는 포함되었으나 유의하지 않아 최종모형에서는 제외되었다.
분석에 사용된 코드를 받아두어야 한다. 여기서는 spss코드로 요청해 보았다.
| 분석에 사용된 코드를 spss로 산출해 주시오. |
아래에서 보듯이 spss syntax를 만들어 주었다. spss에서는 logistic에서 roc 커브를 그려주지 않고 별도 프로시져가 있다. GPT는 그래서 logistic에서 예측값을 저장한 다음, 그것을 ROC 프로시저에서 산출하는 방식으로 코드를 작성했다.
* 로지스틱 회귀분석: pheal (0/1) 예측.
LOGISTIC REGRESSION VARIABLES pheal
/METHOD=ENTER age heal_cond2 gender edu2
/INTERACTIONS=age WITH heal_cond2
/CRITERIA=PIN(.05) POUT(.10) ITERATE(20) CUT(.5)
/PRINT=CI(95) GOODFIT
/SAVE=PRED(predprob) RESID(residual).
LOGISTIC REGRESSION VARIABLES pheal
/METHOD=ENTER age heal_cond2 gender edu2
/INTERACTIONS=age WITH heal_cond2
/SAVE=PRED(proba).
ROC pheal BY proba (PROB)
/PLOT=CURVE
/PRINT=SE COORDINATES
/CRITERIA=CUTOFF(.5).
* 예측확률 0.5 기준으로 이진 예측값 생성.
COMPUTE pred_bin = (proba >= 0.5).
EXECUTE.
* 실제값 vs 예측값 교차표 = 혼동행렬.
CROSSTABS
/TABLES=pheal BY pred_bin
/FORMAT=AVALUE TABLES
/STATISTICS=CHISQ
/CELLS=COUNT ROW COLUMN.